Weaponizing Machine Learning
Table of Contents
Preface
Pointers
- DEF CON 25 (2017) - Weaponizing Machine Learning - Petro, Morris
- Slides
- BishopFox/deephack
- deephack short demo video
Other resources
- DEF CON 25 - Hyrum Anderson - Evading next gen AV using AI
- DEF CON 24 - Clarence Chio - Machine Duping 101: Pwning Deep Learning Systems
- DEF CON 24 - Delta Zero, KingPhish3r - Weaponizing Data Science for Social Engineering
- DEF CON 23 - Packet Capture Village - Theodora Titonis - How Machine Learning Finds Malware
- more on the web…
Before starting
Unfortunately this talk is not focused on technical security aspects, but gives you a clear view on how Machine Learning could be used in Security applications.
You will read a single DEFCON talk resume, but you can go deeper looking here.
Talk
Introduction
Offensive Security point-of-view of artificial intelligence.
There are already softwares that use Machine Learning for Defensive purposes like firewalls for anomalous traffic detection, so we’ll focus on the Offensive purposes in order to create of find already existing tools of this category.
Fields coverage:
- AI
- Programming
- Hacking
Den Petro and Ben Morris from Bishop Fox created a tool named “DeepHack” which uses ML to accomplish SQL injection attack.
SQL
Language used to query a Database in order to add/remove/edit information collected inside of it as records.
SQL injection is a code-injection-based attack triggered by malicious SQL code given, for example, to a web application form that gets data from a database.
It can be used to enumerate a DB or to inject malicious code to the DB server or to achieve other goals.
DeepHack
Let’s think to a typical SQL attack:
How does it work?
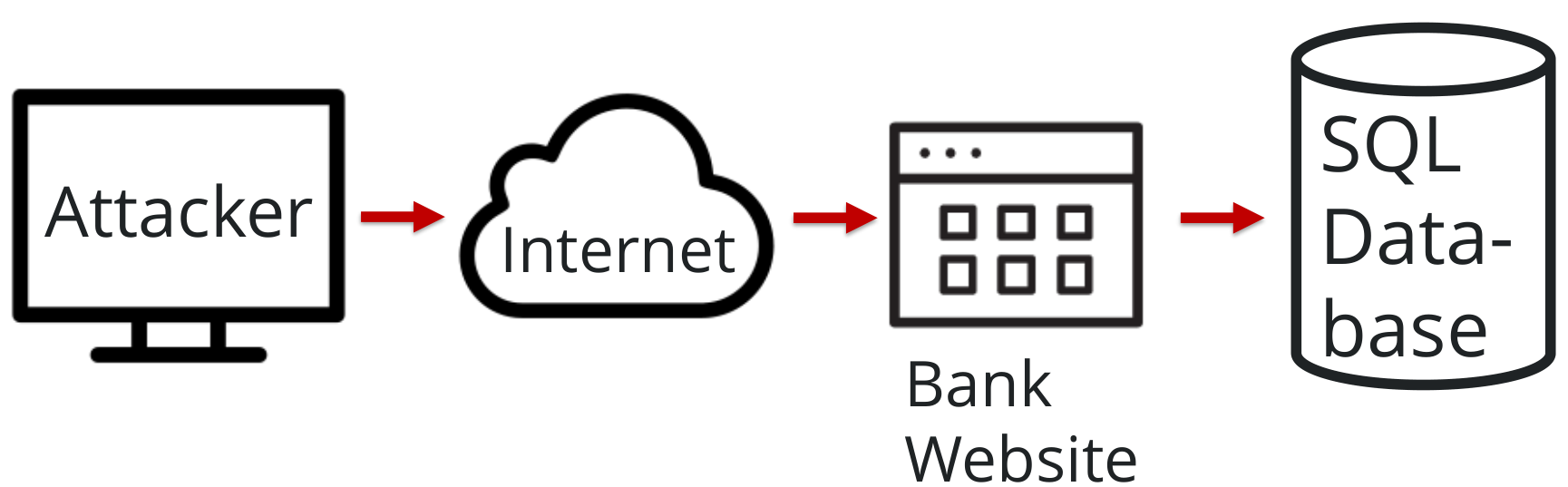
What DeepHack does is “just” to bruteforce characters that are going to compose the SQL statement given to the DB.
Q: Is this yet another SQL injection tool?
No, it isn’t.
There’s something more:
- no SQL statements
- no hard-coded SQL logic
- no info on DB / web-application implementation
are given to the tool.
Q: So how it can perform a SQL query?
Everything about the DB or SQL is discovered and learned by the Machine Learing algorithm just by bruteforcing characters.
The Machine Learning way
Regular program vs AI program
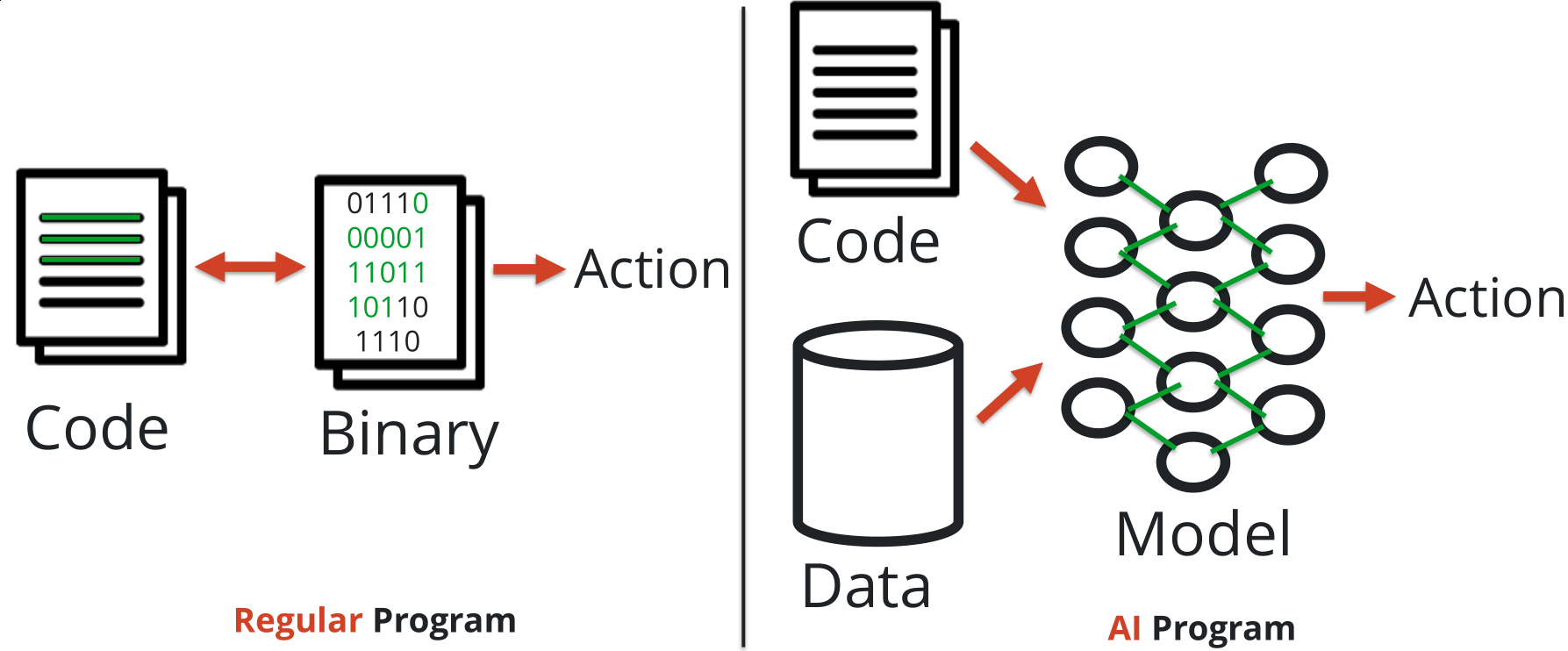
Regular program
Code -> Binary -> Action
Write code, compile it obtaining a binary file with machine instructions that are going to be run on the computer in order to perform a programmed action.
- 1:1 relationship between source Code and Action(s)
- reversable (we know how :D)
- very deterministic path from Code to Action
AI Program
Code + Data -> Model (Neural Network) -> Action
Binary and written code remains, BUT the Model is responsible of taking a decision in order to obtain an Action.
- no conditional logic (if-then-else on a certain state)
- decisions are based on probability…
- and on what happened in the past (Data)
- not deterministic as a regular program
Learning: the mathematical way
Take actions and record the reward that it gets (good/bad feedback), restarting and trying new actions never done before, getting a feedback and so on until it can derive the optimal solution
Complex problems (in the slide the chess game) can’t be represented at all in our computers, so the breakthrough idea of ML is to use mathematical function approximation to represent the problem.
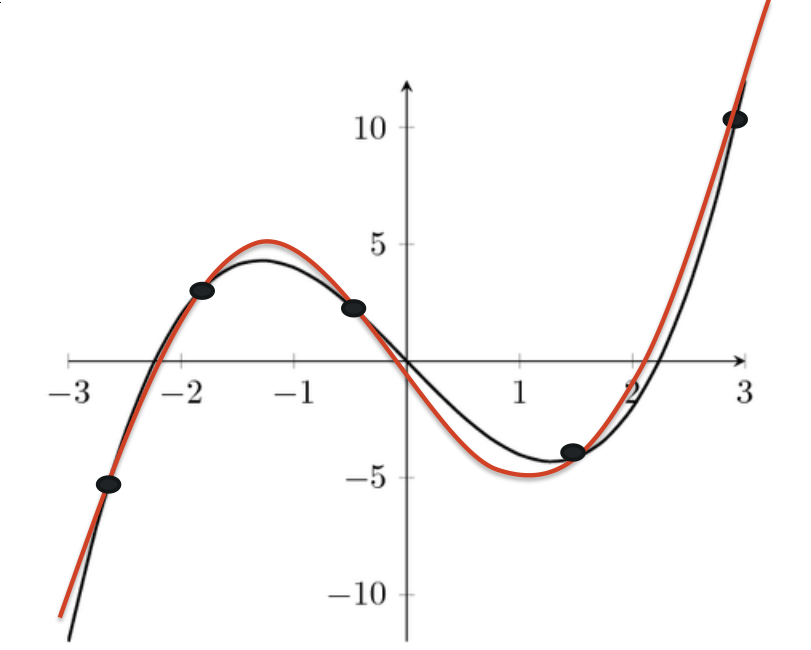
Function approximation (the results) precision (comparing with the wanted function) is directly proportional to the number of actions the ML takes. So you keep sampling until you start getting close to the wanted function.
It’s hard to get a perfect approximation, especially in the real world when you are modeling something more complex than this example. That is one of the core activities when building an AI program. It’s the real part of making the program “learn” with a trial-and-error approach.
ML program fundamentals
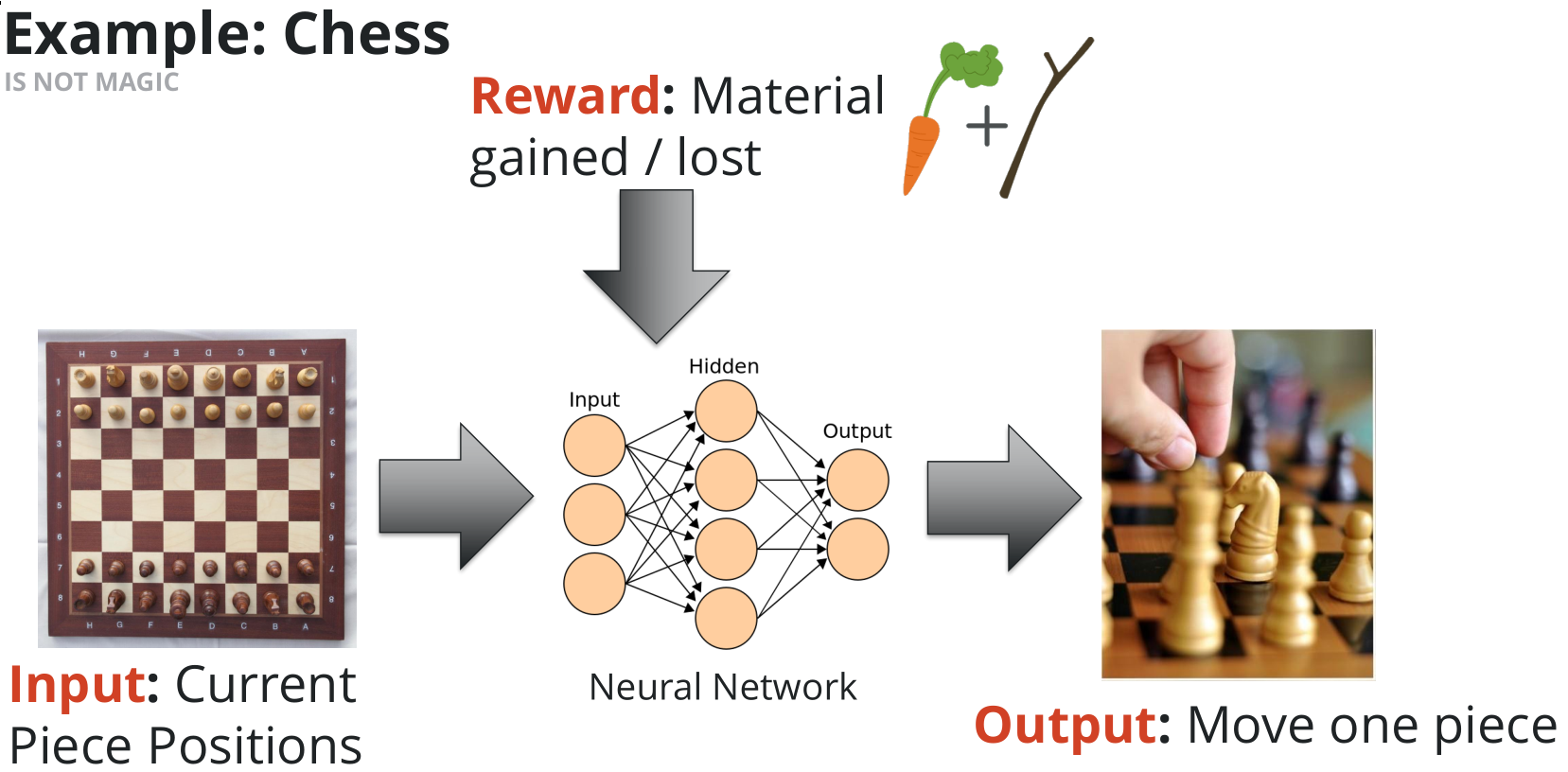
- Input: the environment. Everything that is told to the machine learning program to let it know about its world. That doesn’t need to represent too much data but enough for it to be able to make smart decisions (Chess example: current piece positions)
- Output: the action that is going to be taken (Chess example: move one piece)
- Reward: the output was good or bad? How does it affect the result I want to obtain? (Chess example: good/bad reward for gaining or losing a piece)
Neural networks process all those data.
Training
It is a fundamental step for a ML program.
If you run DeepHack and let it work on a DB server without a training, it will fuck up in no time.
It can still recover and go back into its rails, but it will need some time (and we don’t have it).
It’s good practice to give to the model a good labeled data (or experiences) in order to “train” it.
That data is a collection of past results given back by the ML program and it turns to be useful to bootstrap the program into a better behaviour.

Q: What do you mean with labeled data?
Tons of actions already taken associated with their output.
These data sets can be also built by users: reCAPTCHA is a good example. When you are solving one of them you are feeding and helping the ML algorithm, which decides if you are a bot or not, in its training.
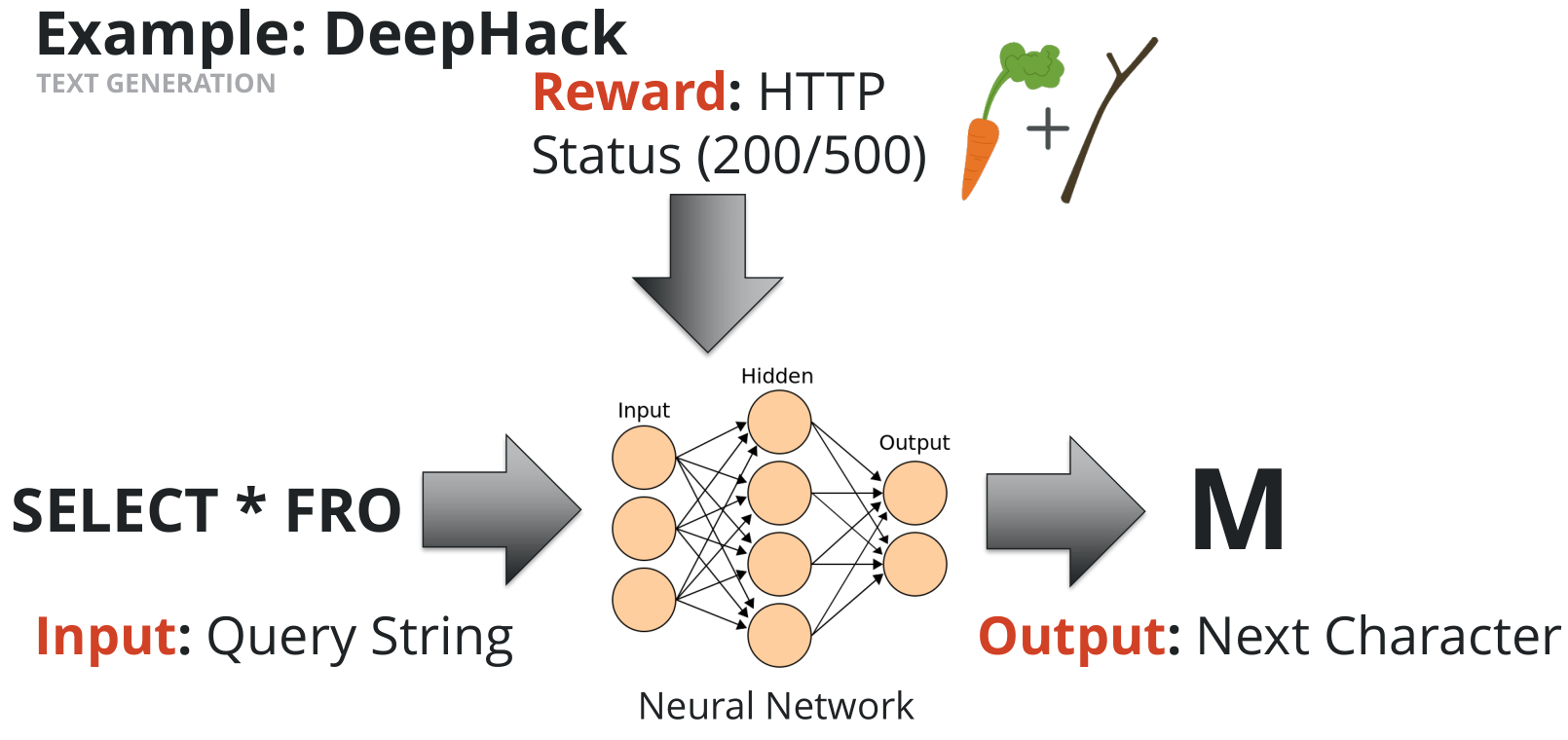
DeepHack
- Input:
SELECT * FRO - Output:
M - Reward: HTTP Status 200 (or 500 if not
M)
The key to get the work done is by iterating this process (bruteforce character by character) until we get a complete SQL statement.
The tool may not work as expected, nevermind, it’s just ML :D.
That’s because ML picks up the next letter using probability distribution across all letters.
In fact, if DeepHack is not given a good starting dataset, it will just talk of food or something else (not SQL) whithout the knowledge of how to recover that.
As said above, DeepHack doesn’t know nothing about the SQL language, DB server or Web application. So you can let it work on a SQLite DB or Postgres (demos) or whatever-you-want DB.
That is an important aspect in order to create a flexible tool (work with different languages) without editing the code: it “only” needs to be trained for the specific job you want.
Code is available in the Github repo. Not security oriented, but useful to learn Machine Learning Python frameworks.
Conclusion
- quality training data is important (and hard to get)
- idea: scrape the internet for SQL strings/structures (better if injection-specific)
- idea: now the ML program can talk SQL but can’t make injection attack, so you can use SQLMap -> too complicated output
- solution: boolean blind injection by bruteforcing character by character
- be careful about what actions you reward and if they’re consistent with the problem rules
- get a gpu (better a lot of them, even in cloud): 20x speedup in training phase (useful when you have to re-train every time you make a change)
- program behaviour is not reversible, not really “debuggable” like we do with regular programs
- program behaviour is not predictable with same code and dataset, in a different time / context execution it can behave differently (open-source release issue)
- responsibility on ML program bad decisions (in complex models like self-driving cars)
- not so difficult programming AI: take a library and code! (tensorflow/keras/pytorch etc.)…
- … but frustrating when you have garbage output and think if you have trained too much or not enough
Future Work
Since this process is giving good results, automatizing of tasks that used to be fuzzy logic, such as:
- webapp fuzzer
- password bruteforcing (word list + rules/patterns already existing in password dump and generating new for human): very good!
- service identification
But at the moment it’s not good at finding new classes of vulnerabilities: ML program doesn’t have the knowledge to decide what is a security risk and what is not.